An important aspect of an outlier detection technique is the nature of the desired outlier. Outliers can be classified into following three categories:
- Point Outliers
- Contextual Outliers
- Collective Outliers.
Point Outliers:If an individual data instance can be considered as anomalous with respect to the rest of data, then the instance is termed as a point outlier. This is the simplest type of outlier and is the focus of majority of research on outlier detection. For example, in Figure 1, points o1 and o2 as well as points in region O3 lie outside the boundary of the normal regions, and hence are point outliers since they are different from normal data points. As a real life example, if we consider credit card fraud detection with data set corresponding to an individual's credit card transactions assuming data definition by only one feature: amount spent. A transaction for which the amount spent is very high compared to the normal range of expenditure for that person will be a point outlier.
Contextual Outliers:If a data instance is anomalous in a specific con-text (but not otherwise), then it is termed as a contextual outlier (also referred to as conditional outlier [1]). The notion of a context is induced by the structure in the data set and has to be specified as a part of the problem formulation. Each data instance is defined using two sets of attributes:
Contextual attributes. The contextual attributes are used to determine the context (or neighborhood) for that instance. For example, in spatial data sets, the longitude and latitude of a location are the contextual attributes. In time series data, time is a contextual attribute which determines the position of an instance on the entire sequence.
Behavioral attributes. The behavioral attributes define the non-contextual characteristics of an instance. For example, in a spatial data set describing the average rainfall of the entire world, the amount of rainfall at any location is a behavioral attribute.
The anomalous behavior is determined using the values for the behavioral attributes within a specific context. A data instance might be a contextual outlier in a given context, but an identical data instance (in terms of behavioral attributes) could be considered normal in a different context. This property is key in identifying contextual and behavioral attributes for a contextual
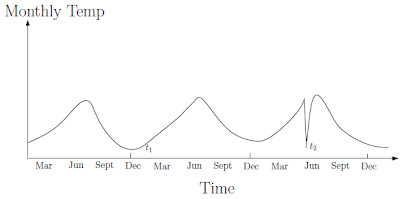
Contextual outlier t2 in a temperature time series. Temperature at time t1 is same as that at time t2 but occurs in a different context and hence is not considered as an outlier.
Contextual outliers have been most commonly explored in time-series data [2] and spatial data [3]. Figure 3 shows one such example for a temperature time series which shows the monthly temperature of an area over last few years. A temperature of 35F might be normal during the winter (at time t1) at that place, but the same value during summer (at time t2) would be an outlier. A six ft tall adult may be a normal person but if viewed in context of age a six feet tall kid will definitely be an outlier.
A similar example can be found in the credit card fraud detection with contextual as time of purchase. Suppose an individual usually has a weekly shopping bill of $100 except during the Christmas week, when it reaches $1000. A new purchase of $1000 in a week in July will be considered a contextual outlier, since it does not conform to the normal behavior of the individual in the context of time (even though the same amount spent during Christmas week will be considered normal).
The choice of applying a contextual outlier detection technique is determined by the meaningfulness of the contextual outliers in the target application domain. Applying a contextual outlier detection technique makes sense if contextual attributes are readily available and therefore defining a context is straightforward. But it becomes difficult to apply such techniques if defining a context is not easy.
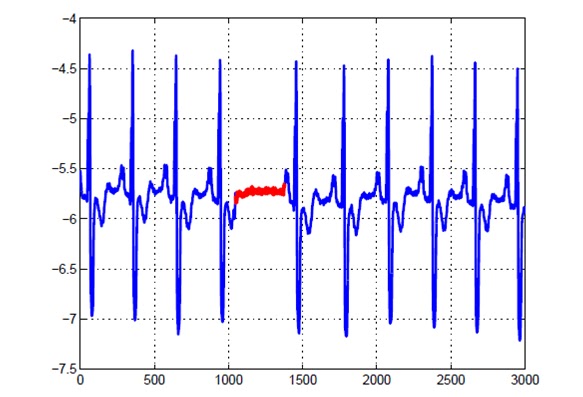
Collective Outliers:If a collection of related data instances is anomalous with respect to the entire data set, it is termed as a collective outlier. The individual data instances in a collective outlier may not be outliers by themselves, but their occurrence together as a collection is anomalous. Figure 4 illustrates an example which shows a human electrocardiogram output [4]. The highlighted region denotes an outlier because the same low value exists for an abnormally long time (corresponding to an Atrial Premature Contraction). It may be noted that low value by itself is not an outlier but its successive occurrence for long time is an outlier.

Collective outlier in an human ECG output corresponding to an
Atrial Premature Contraction.
As an another illustrative example, consider a sequence of actions occurring in a computer as shown below: ……...http-web, buffer-overflow, http-web, http-web, smtp-mail, ftp, http-web, ssh, smtp-mail, http-web, ssh, buffer-overflow, ftp, http-web, ftp, smtp-mail, httpweb…… The highlighted sequence of events (buffer-overflow, ssh, ftp) correspond to a typical web based attack by a remote machine followed by copying of data from the host computer to remote destination via ftp. It should be noted that this collection of events is an outlier but the individual events are not outliers when they occur in other locations in the sequence.
Collective outliers have been explored for sequence data [5,6], graph data [7], and spatial data [8]. It should be noted that while point outliers can occur in any data set, collective outliers can occur only in data sets in which data instances are related. In contrast, occurrence of contextual outliers depends on the availability of context attributes in the data. A point outlier or a collective outlier can also be a contextual outlier if analyzed with respect to a context. Thus a point outlier detection problem or collective outlier detection problem can be transformed to a contextual outlier detection problem by incorporating the context information.
Reference: Forrest, S., Warrender, C., and Pearlmutter, B. 1999. Detecting intrusions using system calls: Alternate data models. In Proceedings of the 1999 IEEE ISRSP. IEEE Computer Society, Washington, DC, USA, 133 - 145.
Goldberger, A. L., Amaral, L. A. N., Glass, L., Hausdorff, J. M., Ivanov, P. C., Mark, R. G., Mietus, J. E., Moody, G. B., Peng, C.-K., and Stanley, H. E. 2000. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for com-plex physiologic signals. Circulation 101, 23, e215 - e220. Circulation Electronic Pages:
http://circ.ahajournals.org/cgi/content/full/101/23/e215.
Kou, Y., Lu, C.-T., and Chen, D. 2006. Spatial weighted outlier detection. In Proceedings of SIAM Conference on Data Mining.
Noble, C. C. and Cook, D. J. 2003. Graph-based outlier detection. In Proceedings of the 9th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM Press, 631 - 636.
Sekar, R., Bendre, M., Dhurjati, D., and Bollineni, P. 2001. A fast automaton-based method for detecting anomalous program behaviors. In Proceedings of the IEEE Symposium on Security and Privacy. IEEE Computer Society, 144.
Song, X., Wu, M., Jermaine, C., and Ranka, S. (2007). Conditional outlier detection. IEEE Transactions on Knowledge and Data Engineering 19, 5, 631-645.
Sun, P., Chawla, S., and Arunasalam, B. 2006. Mining for outliers in sequential databases. In SIAM International Conference on Data Mining.
Weigend, A. S., Mangeas, M., and Srivastava, A. N. (1995). Nonlinear gated experts for time-series – discovering regimes and avoiding overfitting. International Journal of Neural Systems 6, 4, 373-399.